 |
||
| Scientists' Contributions | ||
November 6-7, 2000 Hotel Ibis in Krakow
Air Quality Management In Urban Areas In The Light Of EU Legislation
(Manuscript finalized October 2000, modified for newsletter publication
November, 2000)
Modeling Air Quality Pollutant Impacts
- by
John S. Irwin1
Atmospheric Sciences Modeling Division
Air Resources Laboratory
National Oceanic and Atmospheric Administration
Research Triangle Park, NC 27711
United States of America
- Contents of this paper
-
Abstract
Background
Access to Modeling Tools
Air Dispersion Modeling
Natural Variability and Model Uncertainty
Model Accuracy
Conclusions
Disclaimer
References
Appendix - Terminology
ABSTRACT
Since 1973 the U.S. Environmental Protection Agency (EPA) has provided a selection of numerical air quality dispersion modeling methods. Where once these models were distributed using computer magnetic tape, the distribution now is made via the Support Center for Regulatory Air Models which is available through an Internet web page, http://www.epa.gov/scram001. The goal of this presentation is to provide a basic understanding of the kinds of air dispersion models available and the purposes for which these dispersion models are best used.
For pollutants that can reasonably be treated as inert,
Lagrangian models are made available. Such models provide direct tracking of
individual impacts from each of the sources simulated. The spread (or
dispersion) of particles or gases within a smoke plume as it is transported
downwind is often approximated as having a Gaussian distribution in the
vertical and horizontal. This approximation regarding dispersion has been
adapted into many Lagrangian air dispersion models, each of which has been
tailored to treat a different set of situations, such as: dispersion from
building complexes, near roads and intersections, near coastal areas. Eulerian
grid models are made available for best treatment of the often complex
chemistry of chemically active pollutants, where the pollutant of interest is
primarily the result of reactions during transport (as opposed to being emitted
directly into the atmosphere). The chemical rates of production of secondarily
formed pollutants are controlled by the combined effects of the emissions from
all sources. Eulerian grid models typically are stated relative to a volume of
air fixed in space, through which the air moves. Following a brief overview of
Eulerian and Lagrangian modeling, a discussion is presented of the strengths,
limitations and accuracy of local-scale air quality models.
The passage of the Clean Air Act in 1963 and its amendments
(U.S. Congress, 1963), in particular the amendments of 1970 and 1977,
formalized the need within the United States of America for routine access to
air quality simulation models. This act and its amendments established the
concept of air quality goals to
protect public health and welfare. These goals were expressed in the form of
National Ambient Air Quality Standards (NAAQS), which were specific maximum
permitted air pollution levels. Limiting existing and future emissions so as
to attain and maintain these national standards became the responsibility of
the states. The states were charged with developing and implementing detailed
plans and procedures (State Implementation Plans, SIPs) that when enforced
would assure attainment of the NAAQS. Air quality simulation models became the
means by which demonstrations could be made that a source's emissions would
not endanger attainment of the NAAQS.
Figure 1 provides a schematic representation of some of the
concepts envisioned in the Clean Air Act. At the bottom of the cycle depicted,
the basic decisions are whether human health and welfare are sufficiently
protected. If they are not, then knowing the costs associated with alternative
plans for reducing the health and welfare impacts, provides useful information
for deciding next steps. The goal of effective costs/benefit analyses is to
address at least the major consequences and relationships of alternative air
pollution prevention strategies. Removing pollutants from stack gases before
they are released to the atmosphere creates an associated cost for the disposal
of the pollutants removed. The disposal of these pollutants must be properly
addressed, otherwise the air pollution problem has only been transferred to
another medium, such as the soil, which may in fact have a more severe and
costly environmental impact.
If it is determined that adjustments, e.g. emission
limitations, are needed to attain the NAAQS, the next logical step (moving
counter-clockwise), is to develop an emission inventory. Developing an
inventory is an iterative process. An initial accounting of major known
sources is developed. This initial inventory is used as input to an air
quality simulation model, and the modeled concentration values are compared to
available measured concentration values. An assessment is made as to whether
the differences seen are 1) within acceptable bounds given known levels of
natural variability, 2) resulting from deficiencies in the application of the
air quality model, or 3) deficiencies in emission inventory. This iterative
process may involve use of at first rather simplistic air quality simulation
models, to provide first order checks of the emission inventory. Then
progressively more refined air quality simulation models can be used as needed
to further refine both the emission inventory and the air quality simulation to
the level necessary for the determination of health and welfare impacts.
Reducing ambient air impacts from specific sources can be
accomplished by various means, such as: changing to different fuels, adding
control equipment to trap material before it is released to the atmosphere,
upgrading industries to use more modern (less polluting) equipment or practices.
Each option alters the emissions and each option carries with it an associated
cost.
To provide access to available dispersion models, a User's
Network for Applied Modeling of Air Pollution (UNAMAP) was developed in 1972
(Turner et al., 1989). Six air quality simulation models were made available
to four mainframe computers that were accessible to the public. In 1973 this
system was replaced by making available to the public a computer tape of the
FORTRAN source codes for the six models through the National Technical
Information Service (NTIS). By 1988, version 6 of UNAMAP provided codes for 24
different simulation models, and 19 associated processors and utility programs.
Updating the models (many had gained regulatory status) was carefully managed
and coordinated within the Environmental Protection Agency (Environmental
Protection Agency, 1986). These demands and the advent of electronic Bulletin
Board Systems (BBS) prompted conversion to the Support Center for Regulatory
Air Models (SCRAM) BBS in May, 1989. Initially SCRAM consisted of 18 models
and utility programs, with a total of about 50 files available for download
through 4 phone modem lines. Download activity was around 30 files per week
during the first few months and grew to an average of about 2100 files per
week by 1995. In 1995, 40 modem lines were available at any given moment via
EPA's Technology Transfer Network (TTN). The TTN consisted of over 15
separate BBS systems, providing a vast variety of information and services
related to air pollution control. Over time, the purpose of SCRAM was
expanded to include not only software for various air simulation models, but
also modeling guidance documents. Today, there are 46 models and utility
programs made available via SCRAM, with over 3500 files available for download.
On April 23, 1996, SCRAM became accessible via Internet. The web page address
is:
http://www.epa.gov/scram001.
(Note, a web page of interest in Europe is
http://aix.meng.auth.gr/database/index.html.)
Air quality simulation models can be characterized broadly
by the manner in which the fate and transport of pollutants within the air are
simulated. Models of physical processes whose equations are stated relative to
a volume of air that follows the dispersing material during transport downwind
can be referred to as Lagrangian models. Models of physical processes whose
equations are stated relative to a volume of air fixed in space, through which
the air moves can be referred to as Eulerian models. As discussed below,
selecting an air simulation model for use for a particular situation involves
not only an awareness of the tradeoffs in using different model constructs and
the pollutants being modeled, but also includes among other factors, the
emission control options being considered and the chemical and physical process
being simulated. Since this is a general discussion to emphasize principles,
specific references have purposely not been provided. A useful general
reference that discusses much more than will be merely introduced here, and
itself, provides an excellent cross reference to other references, is Randerson
(1984).
Shown in Figure 2 is a first-order implementation of a grid
model. In this implementation, the entire modeling domain is one box.
The emissions within this volume from area, point and line sources are assumed
to be instantaneously well-mixed throughout the volume. The chemical reactions
resulting from the interaction of the emitted species with each other and with
incoming solar radiation are then simulated to produce volume average
concentrations as a function of time. One-volume grid models are often used as
screening aids in assessing potential problems in the application of more
comprehensive models. A discussion and illustration of a popular single-cell
grid model, OZIP, often used for screening analyses is provided on the Internet at
http://www.shodor.org/ekma/model/ekma.html.
A more complete characterization of the processes is obtained by dividing the
modeling domain into horizontal grid cells, stacked in the vertical. This
allows elevated point source emissions to be injected into the simulation into
cells aloft and near-surface emissions to be injected in the grid cells next to
the surface, to provide a more realistic characterization of the processes,
(Environmental Protection Agency, 1990). Within these multi-grid models, the
emissions are well-mixed within each cell they are emitted. Advection between
grid cells occurs over time, and is typically a function of the time-dependent
three-dimensional meteorological conditions within the modeling domain.
The impact of secondarily formed pollutants typically
involves primary precursor emissions from a multitude of widely dispersed
sources, such as automobiles, power plants, trees and vegetation. The formation
through chemical and physical processes of pollutants during transport downwind
takes time. The development of emission control strategies for secondarily
formed pollutants rarely involves adjustments unique to particular individual
sources. Hence, Eulerian grid models are very useful for assessing the effects
of secondarily formed pollutants.
Shown in Figure 3 is a popular implementation of a
steady-state Lagrangian model, namely the Gaussian plume model (Turner, 1970).
Based on field tests of tracer gas dispersion, it has been determined that the
crosswind concentration profile along the surface, downwind from a point source
release, appears to generally have a bell-shaped profile (Gaussian). Even the
vertical profile can be often approximated as having a Gaussian profile.
Empirical data provide a basis for estimating the growth in the vertical and
lateral dimensions of the dispersing plume as it moves downwind. Adjustments
can be made to account for the fact that the vertical and lateral growth of the
dispersing material will be faster over large trees and bushes, than over large
lakes or bodies of water. Algorithms have been developed to account for the
fact that most industrial source emissions are hotter than the surrounding
ambient air, and tend to rise. Through the years, other adaptations have been
developed, such as, accounting for possible capture of the emissions upon
release within the wake of nearby buildings, and accounting for alteration in
the downwind course of the plume and rate of dispersion due to a hill being in
the path of the plume. The plume model is limited to downwind distances for
which the dispersive state of the atmosphere can be assumed to be steady-state.
This limits the plume model to distances on the order 10 to 20km.
These same Lagrangian concepts can be adapted to a puff
model (see Figure 4), where the emission is simulated as a series of
overlapping puffs, which then allows nonsteady-state conditions (in time or
space) to be appropriately simulated. After several hours, natural variations
in wind direction in time and space, will cause the plume to have a serpentine
shape, which can be well-approximated using a puff model. Puff models can
approximate the transport within valleys and around hills, where the wind
pattern may be strongly affected by warm upslope winds during the day and
downslope (drainage) winds during the night. In contrast to plume models, puff
models are not founded on a premise that the transport downwind is sufficient
that dispersion in the along wind direction can be neglected. Puff models
provide useful results even during stagnation conditions, when winds become
light and variable.
The major impacts from primary emissions are usually near
the release, typically involving transport downwind of less than 15km.
Developing effective plans to mitigate impacts from primary emissions often
involves unique limitations being placed on individual sources. One of the
strengths of Lagrangian models is that they can be fashioned to address very
local (source-specific) factors that greatly affect the local (near-field)
dispersion and related concentration values. Since Lagrangian models track
independently the contributions from each source, they are very useful for
assessing the effects of primary emissions of pollutants.
As discussed in the Terminology Appendix, variability refers
to the observable variations that happen naturally, whereas, uncertainty refers
to differences between observed and modeled values that represent a lack of
knowledge (modeling skill). These differences are mostly the fault of model
formulation uncertainty, but also arise in characterizing the model input. We
can speak of model uncertainty as being composed of:
At best air dispersion models provide an unbiased estimate
of the average concentration expected over all realizations of an ensemble.
An estimate of an ensemble can be developed from a set of experiments having
fixed external conditions (Lumley and Panofsky, 1964). To accomplish this, the
available concentration values are sorted into classes characterizing ensembles.
For each of the ensembles thus formed, the difference between the ensemble
average and any one observed realization (experimental observation) is then
ascribed to unresolved natural variability, whose variance, where Co is the observed concentration seen within a realization; the angle
brackets refer to an average over all available realizations within a given
ensemble. < Co > is thus the estimated ensemble average, which is what a model
(deterministic or stochastic) is attempting to characterize, and the ensemble
refers to the infinite population of all possible realizations meeting the
chosen characteristics of the ensemble. In practice, we will only have a small
sample from this ensemble. Available estimates suggest An illustration of unresolved concentration variability is
presented in Figure 5. Project Prairie Grass (Barad, 1958, and Haugen, 1959) is
a classic tracer dispersion experiment, where sulfur-dioxide (SO2) was released
from a small tube placed 46 cm above the ground. Seventy 20-minute releases
were conducted during July and August 1956, in a wheat field near O'Neil,
Nebraska. The wild hay was trimmed to a uniform height of 5 to 6 cm in height.
Sampling arcs were positioned on semicircles centered on the release, at
downwind distances of 50, 100, 200, 400 and 800m. The samplers were positioned
1.5m above the ground, and provided 10-minute concentration values.
For the purpose of illustrating unresolved concentration
variability, small ensembles of six experiments along the 400-m arc have been
grouped together in Figure 5 using the inverse of the Monin-Obukhov length, L,
a stability parameter. L is negative when the surface is heated (upward heat
flux), and positive during when the surface is cooled (downward heat flux). 1/L
approaches zero, when the surface layer of the atmosphere approaches neutral
stability conditions. To group the results of the six experiments together, the
concentration values have been normalized by multiplying the concentration
values by U/Q, where U was defined as the wind speed observed at 8m above the
ground and Q is the emission rate. The solid line shown for each group is a
Gaussian fit to the results for the six experiments in the group. As mentioned
earlier in this discussion, the lateral dispersion is seen to be well
approximated by a Gaussian shape. The scatter of the normalized concentration
values about this Gaussian fit can be statistically analyzed to provide an
estimate of the concentration variability not characterized by the Gaussian
fit. From analyses of this and another tracer study (involving tracer injected
into the emissions of a 186m stack of an operating power plant), the
stochastic fluctuations (unresolved natural variability) was investigated by
analyzing the distribution of Co/< Co > for centerline concentration values. This
distribution was found to have a somewhat log-normal distribution with a
standard geometric deviation of order 1.5 to 2 (Irwin and Lee, 1996). These
results suggests that centerline concentration values from individual
experiments may typically deviate from the ensemble average maximum by as much
as a factor of 2 due to unresolved natural variability (formulation uncertainty).
Given that models are attempting to characterize how the
ensemble mean varies (< Co > in equation 1), one might ask why models are not
fashioned that explain more of the physical processes, and thereby characterize
more of the explainable variations. This would reduce the amount of unexplained
natural variations ( Using a Gaussian plume model, Irwin et al. (1987)
investigated the uncertainty in estimating the hourly maximum concentration
from elevated buoyant sources during unstable atmospheric conditions due to
model input uncertainties. A numerical uncertainty analysis was performed using
the Monte-Carlo technique to propagate the uncertainties associated with the
model input. Uncertainties were assumed to exist in four model input
parameters: wind speed, standard deviation of lateral wind direction
fluctuations, standard deviation of vertical wind direction fluctuations, and
plume rise. It was concluded that the uncertainty in the maximum concentration
estimates is approximately double the uncertainty assumed in the model input.
For instance, if 50% of the input values are within 30% of their error-free
values, then 50% of the estimated maximum concentration values will be within
60% of their error-free values. Using a photochemical grid model, Hanna et al.
(1998) investigated the uncertainty in estimating domain-wide hourly maximum
ozone concentration values near New York City for July 7-8, 1988. Fifty
Monte-Carlo runs where made in which the emissions, chemical initial
conditions, meteorological input and chemical reaction rates where varied
within expected ranges of uncertainty. The amount of uncertainty varied,
depending on the variable. Those variables with the least assumed uncertainty
(most of the meteorological inputs) were assumed to be within 30% of their
error-free values 95% of the time. Larger uncertainties were generally assumed
for the emissions and reaction rates. They found the domain-wide maximum hourly
averaged ozone ranged from 176 to 331 ppb (almost a factor of two range). These
two investigations reveal that uncertainty in modeling results due to model
input uncertainties is quite large, regardless of whether the model is a
Gaussian plume model, a photochemical grid model, or whether the specie being
modeled is inert or chemically reactive.
Irwin and Smith (1984) warned that disagreement between the
indicated wind direction and the actual direction of the path of a plume from
an isolated point source is a major cause for disagreement between model
predictions and observations. Plumes from such sources typically expand at an
angle of approximately 10 degrees, as they proceed downwind, and seldom is this
angle larger than 20 degrees. With such narrow plumes, even a 2-degree error in
estimating the plume transport direction can cause very large disagreement
between modeled and observed surface concentration values. Weil et al. (1992)
analyzed nine periods from the EPRI Kincaid experiments, where each period was
about 4 hours long. They concluded that for short travel times (where the
growth rate of the plume's width is nearly linear with travel time), the
uncertainty in the plume transport direction is of the order of 25% of the
plume's total width. Farther downwind, where the growth rate of the plume's
width is less rapid, the uncertainty in the plume transport direction is larger
than 25% of the plume's total width. Uncertainty in plume transport
characterization is thus seen to be so large as to preclude meaningful
comparison of modeled and observed concentration values fixed space. Unless
some adjustment (shifting in modeled and observed patterns) is made, the
correlation will be nearly zero, even for an "error-free" model suffering only
from uncertainties in the characterization of the transport.
This section has presented an overview of why modeled and
observed values differ. The observations are envisioned as being composed of an
ensemble means about which there are deviations either resulting from
measurement uncertainty or uncharacterized natural variability (a component of
model formulation uncertainty as it represents physical processes not accounted
for in the modeling). The model values are envisioned as being composed of an
ensemble means about which there are deviations either resulting from input
(representativeness) uncertainty or model formulation errors. It was discussed
that differences arising from unresolved natural variations and input
representativeness are large, regardless of whether we are speaking of a
Lagrangian model, or an Eulerian grid model, or whether the specie being
modeled is inert or chemically reactive. Examples were provided that suggest
that the effects of input uncertainty can be amplified within the modeling
(e.g., doubled), and that uncertainty in the model formulation can easily lead
to variations of order a factor of two or more.
Most model evaluation results currently available in the
literature are for applied dispersion models that use ensemble average
characterizations of the vertical and lateral dispersion, the chemical
transformations, and the physical removal processes. Thus, these applied
dispersion models can only provide a description of the average fate and
dispersion of pollutants to be associated with each possible ensemble of
conditions. The unresolved natural variability can and will result in large
deviations to be seen in comparisons of individual observations (which are
individual realizations from an ensemble of realizations) with modeling results
(which are characterizing the ensemble average result).
Figure 7 shows a comparison of observed and simulated daily
maximum 1-hour ozone concentration values. These results are from a compilation
of a series of photochemical model simulations conducted within the United
States (Environmental Protection Agency, 1996). These domain-wide 1-hour maxima
are not paired in space, so for a complete evaluation of model performance both
spatial and temporal analyses of the matching between the simulated and
observed concentration values would be desirable. For the 129 comparisons shown
in Figure 7, the average fractional bias, FB, is 0.2% with a standard deviation
of 19%. The fractional bias was defined as
FB = 2(e-o)/(e+o),
where e and o are
the simulated and observed values respectively. Over 90% of the simulation
results are within 30 of observed values. These results are typical of those
found by other investigators. Reviews of past Eulerian grid model evaluation
studies suggest that the accuracy of hourly averaged ozone simulations is of
order 35 to 40 (for example, Tesche, 1988). The spatial pattern for surface
ozone concentration values is typically a broad flat maximum with weak spatial
gradients. Localized areas with strong gradients in ozone concentration are
found in the near vicinity of sources emitting large amounts of nitrogen
oxides, which can locally deplete the ozone. Given a reasonably good precursor
inventory, one would expect the ozone pattern to be well simulated. Sources
with large emissions of nitrogen oxide should be easy to identify. The
production of ozone is strongly forced to track the presence of sunlight and
the precursor emissions are often strongly correlated with surface temperatures,
so the model estimates are forced somewhat to show good correlation in time
(assuming meteorological inputs are adequately characterized).
In recent years, more attention is being given to assessing
the performance of Eulerian grid models in characterizing concentrations of
primary pollutants. Studies as Kumar et al. (1994), suggest that large
differences are seen when comparisons are made involving primary pollutants.
Differences seen for primary pollutants are typically an order of magnitude
larger than those seen for the reactive (secondarily formed) pollutants. The
surface concentration values of primary pollutants are typically one of
localized maxima and minima, surrounded by strong gradients. This is a
difficult pattern to characterize. The simulation results are strongly
dependent on proper characterization of the emissions and on the sophistication
brought to bear on the analysis and characterization of the time and space
varying three-dimensional wind field. One of the more problematic inputs for
grid models is the spatial and temporal characterization of the precursor
emissions, which are often deduced from assumptions of land use, activity
patterns, traffic flows, etc., rather than on direct measurements of emissions.
Figure 8a shows a comparison
of observed and simulated
SO2 concentration values in the vicinity of the Clifty Creek power
plant which is located in a rural area near Madison, Indiana in the United
States. There were 6 air quality monitors near this power plant, ranging in
distance from 3 to 15 km from the power plant. This power plant has six
coal-fired boilers each capable of producing 217 megawatts of power. For each
pair of boilers there is one 208-m stack. The average hourly SO2
emission rate for 1975 and 1976 was 8.67kg/s. For each year (1975 and 1976)
the maximum observed and simulated SO2 concentration value for each
receptor is shown for several averaging times, ranging from the 1-hour maximum
to the annual average. Data files from Environmental Protection Agency (1982)
for the CRSTER dispersion model (Environmental Protection Agency, 1977) were
used to construct the data shown in Figure 8a.
Through the years, CRSTER has
been replaced by other Gaussian plume dispersion models, but the comparisons
shown in Figure 8a are typical of those
summarized in Hanna (1993) for
characterization of SO2 emissions from isolated power plants located
in rural areas of the United States.
The trend to increasingly underestimate the maximum
concentration as averaging time increases can be summarized using the average
fractional bias, FB. The average FB for each averaging time is: 24% (1-hr), 5%
(3-hr), -6% (12-hr), -9% (24-hr), -43% (720-hr), and -77% (annual average). The
standard deviation of FB (a measure of relative scatter) is relatively
independent of averaging time, ranging from 34 to 47%. If we summarize these
results by stability, it can be shown that there is a bias to overestimate
concentrations during unstable conditions and to underestimate concentrations
during stable conditions. The bias seen in the model performance may in part be
traceable to the use of the Pasquill-Gifford dispersion parameters (Turner,
1970), in which the lateral dispersion has an implied averaging time of three
minutes (hence the simulated lateral dispersion is too narrow for
characterization of 1-hour average dispersion), and the vertical dispersion is
typical for ground-level releases (which has various deficiencies for
characterizing dispersion from tall stack emissions). Studies during the late
1980's of tall stack dispersion in convectively unstable conditions have shown
that standard Gaussian plume models cannot properly simulate the effects on
dispersion of the highly organized convective eddies. As a consequence,
Gaussian plume models like CRSTER tend to underestimate maximum surface
concentration values from tall stack emissions during convectively unstable
conditions.
Figure 8b shows the comparison of observed and simulated
SO2 concentration values for 1976 in the vicinity of St. Louis,
Missouri in the United States. Seven of these monitors were within 13 km of
downtown St. Louis, five were within 13 to 36 km, and the remaining site was
about 50 km north of the downtown area. The SO2 emission inventory
included 208 point sources and 1989 area sources. Although the area sources
only accounted for about 3.5% of the 29.76kg/s of total SO2
emissions, the simulated area source impacts were 14 to 67% of the annual
average concentration values for the 13 downtown monitors (Irwin and Brown,
1985). The comparison results shown in Figure 8b are listed in Turner and Irwin
(1983), and are for RAM, a Gaussian plume dispersion model that is tailored for
urban applications. The average FB for each averaging time is: 0% (1-hr), -18%
(3-hr), -35% (24-hr), and -2% (annual average). The standard deviation of the
FB varies as averaging time varies, as: 59% (1-hr), 46% (3-hr), 60% (24-hr),
and 33% (annual average). The results shown in Figure 8b are typical of those
summarized in Hanna (1993) for characterization of SO2 emissions in
urban areas of the United States. The dispersion parameters in RAM are based on
tracer studies of dispersion conducted in an urban area. The tracer releases
were conducted from ground-level releases and from the roof of a three-story
building. The averaging time of these tracer releases (and hence the urban
dispersion curves in RAM) is approximately one hour.
Within the United States emphasis has been placed on the
development, evaluation and application of air quality simulation models that
allow development of air quality management plans to achieve defined national
air quality goals. These plans involve development of emission control
strategies sometimes for individual sources ("primary" impacts associated with
pollutants emitted directly into the atmosphere) and sometimes for classes of
sources ("secondary" impacts associated with pollutants formed during
transport). Part of the decision of which model to select is dictated by
ensuring that the appropriate physical processes are addressed by the model.
But, another part of the decision in model selection is the recognition that
every model is a compromise, in that not all processes are included or else the
computational demands would become not only excessive but highly uncertain.
Hence, model selection often involves expert judgment based on actual
experience in the use and application of the various models available.
Typically Eulerian grid models cannot treat individual
source impacts, unless the emissions from the individual source are a
significant fraction of the domain total emissions, and these impacts are
several grid cells from the source. This limitation arises from the fact that
current grid models uniformly mix the emissions within the grid cell, and thus
do not properly address the initial growth and dispersion of the pollutants.
Since grid models are most often used to address impacts from pollutants that
are formed from other primary emissions, the lack of treatment of initial
dispersion effects is typically assumed to be tolerable. Recent studies are
showing that better characterization of the chemical reactions may require more
direct and complete treatment of the initial dispersion effects. Hence, in the
future we can expect the more advanced chemical models to be "puff-in-grid"
models, where initial "sub-grid" dispersion will be treated by a puff model.
Typically Lagrangian plume and puff models can, at best,
only treat chemical processes that can be approximated as simple linear
transformations in time. But Lagrangian plume and puff models can track
individual source impacts, allowing for development of source specific air
pollution control strategies. Since the uncertainties in the characterization
of the direction of transport are of the order of the actual plume width, large
differences are seen when concentrations are paired in time and space. But when
comparisons are made of observed and simulated frequency distributions for
fixed receptors, current applied plume and puff models typically provide
estimates of maximum concentration values within a factor of two or three of
those observed. These differences are an order of magnitude larger than those
seen for estimates of secondary pollutants, but are understandable when one
considers the lack of any strong constraints in the dispersive processes that
would ensure correlation in time. Also, the dynamic range of concentrations of
the secondary pollutants is typically much smaller than the primary species.
Regardless of whether the model is Eulerian or Lagrangian, modeling the
transport and dispersion of inert pollutants appears to be an order of
magnitude more difficult than simulation of secondarily formed pollutants whose
reaction rates are strongly correlated by the availability of sunlight, and for
which offsetting bias in complex chemistry may mask model deficiencies.
Recent model performance evaluations suggest that much of
the differences seen between modeling results and observations for inert
tracers may result from unresolved natural variability and input data
representativeness. Future development of the model performance evaluation
methods will likely devote more attention to developing objective methods for
discerning whether the differences seen in model performance are significant in
comparison to differences arising from a combination of model uncertainty and
unresolved natural variability.
The information in this document has been funded in part by
the United States Environmental Protection Agency under an Interagency
Agreement (DW13937039-01-06) to the National Oceanic and Atmospheric
Administration. It has been subjected to Agency review for approval for
presentation and publication. Mention of trade names or commercial products
does not constitute endorsement or recommendation for use
Barad, M.L., (Editor) (1958): Project Prairie Grass, A Field Program In
Diffusion. Geophysical Research Paper, No. 59, Vol I and II, Report
AFCRC-TR-58-235, Air Force Cambridge Research Center, 439 pp.
A review of the literature reveals a diversity of
definitions for terms used in model performance evaluations. To avoid confusion
and misunderstandings, it would be helpful to achieve some harmonization about
terminology and its use. We offer some definitions for consideration.
BACKGROUND
ACCESS TO MODELING TOOLS
AIR DISPERSION MODELING
Eulerian Models
Lagrangian models
NATURAL VARIABILITY, MODEL UNCERTAINTY AND MODEL ACCURACY
Natural Variability and Uncertainly
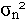 , can be
expressed as (Venkatram, 1988):
, can be
expressed as (Venkatram, 1988):
= < ( Co - < Co > )2 >
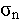 may be large, of
order < Co > (Hanna, 1993).
is equation 1). As is explained in the following
paragraphs, experiences to date suggest that parsimony (economy or simplicity
of assumptions) is a desired trait in modeling. As illustrated in Figure 6, as
the model formulation increases in complexity (to explicitly treat more
physical processes), we increase the number of input variables, which increases
the likelihood of degrading the model's performance due to data
representativeness uncertainty.
may be large, of
order < Co > (Hanna, 1993).
is equation 1). As is explained in the following
paragraphs, experiences to date suggest that parsimony (economy or simplicity
of assumptions) is a desired trait in modeling. As illustrated in Figure 6, as
the model formulation increases in complexity (to explicitly treat more
physical processes), we increase the number of input variables, which increases
the likelihood of degrading the model's performance due to data
representativeness uncertainty.
Model Accuracy
CONCLUSIONS
DISCLAIMER
REFERENCES
Environmental Protection Agency, (1977): User's manual for
single-source (CRSTER) model. EPA-450/2-77-013. U.S. Environmental Protection
Agency, Office of Air Quality Planning and Standards, Research Triangle Park,
NC 27711, 303 pages.
Environmental Protection Agency, (1982): Evaluation of Rural Air
Quality Simulation Models. EPA-450/4-83-03. U.S. Environmental Protection
Agency, Office of Air Quality Planning and Standards, Research Triangle Park,
NC 27711, 300 pages
Environmental Protection Agency, (1986): Guideline On Air Quality
Models (Revised). EPA-450/2-78-027R. U.S. Environmental Protection Agency,
Office of Air Quality Planning and Standards, Research Triangle Park, NC 27711,
290 pages
Environmental Protection Agency, (1990): User's Guide for the Urban
Airshed Model, Volume 1: User's Manual for UAM (CB-IV). EPA-450/4-90-007A. U.S.
Environmental Protection Agency, Office of Air Quality Planning and Standards,
Research Triangle Park, NC 27711, 260 pages.
Environmental Protection Agency, (1996): Compilation of Photochemical
Models' Performance Statistics for 11/94 Ozone SIP Applications.
EPA-454/R-96-004. U.S. Environmental Protection Agency, Office of Air Quality
Planning and Standards, Research Triangle Park, NC 27711, 156 pages.
Hanna, S.R., "Air Quality Model Evaluation and Uncertainty", Journal
of the Air Pollution Control Association, Vol. 38, No. 4, 1988, pp. 406-412.
Hanna, S.R., (1993): Uncertainties in Air Quality Model Predictions,
Boundary Layer Meteorology, Vol. 62, pp. 3-20.
Haugen, D.A., (Editor) (1959): Project Prairie Grass, A Field Program
In Diffusion, Geophysical Research Papers, No. 59, Vol III, AFCRC-TR-58-235,
Air Force Cambridge Research Center, 673 pp.
Irwin, J.S. and Brown, T.M., (1985): A sensitivity analysis of the
treatment of area sources by the Climatological Dispersion Model. Journal of
Air Pollution Control Association. (35):359-364.
Irwin, J.S. and Lee, R.F., (1996): Comparative Evaluation of Two Air
Quality Models: Within-Regime Evaluation Statistic, 4th Workshop on
Harmonization within Atmospheric Dispersion Modeling for Regulatory Purposes.
Oostende, Belgium, May 1996, VITO Report E&M, RA9603, pages 535-542. (In press)
International Journal of Environment and Pollution.
Irwin, J.S. and Smith, M.E., "Potentially Useful Additions to the Rural
Model Performance Evaluation", Bulletin American Meteorological Society, Vol
65, 1984, pp. 559-568.
Irwin, J.S., Rao, S.T., Petersen, W.B., and Turner, D.B., "Relating
error bounds for maximum concentration predictions to diffusion meteorology
uncertainty", Atmospheric Environment, Vol. 21, 1987, pp. 1927-1937.
Kumar, N., Russell, A.G., Tesche, T.W., and McNally, D.E., (1994):
Evaluation of CALGRID using two different ozone episodes and comparison to UAM
results. Atmospheric Environment. Vol. 28(17):2823-2845.
Lumley, J.L. and Panofsky, H.A., (1964): The Structure of Atmospheric
Turbulence. Wiley Interscience, New York, 239 pp.
Randerson, D., (Editor) (1984): Atmospheric science and power
production. DOE/TIC-27601 (NTIS document DE84005177). National Technical
Information Service, U.S. Department of Commerce, Springfield, VR, 850 pp.
Schere, K.L. and Demerjian, K.L., (1984): User's guide for the
photochemical box model (PBM). EPA-600/8-84-022a. U.S. Environmental Protection
Agency, Office of Research and Development, Research Triangle Park, NC 27711,
119 pages
Tesche, T.W., (1988): Accuracy of Ozone Air Quality Models. Journal of
Environmental Engineering. Vol. 114(4):739-752.
Turner, D.B., (1970): Workbook of atmospheric dispersion estimates.
Publication AP-26, (NTIS PB 191 482). Office of Air Programs, U.S.
Environmental Protection Agency, 84 pp.
Turner, D.B. and Irwin, J.S., (1983): Comparison of sulfur dioxide
estimates form the model RAM with St. Louis RAPS measurements. Air Pollution
Modeling and Its Application II. Plenum Publishing Company, N.Y. pages 695-707.
Turner, D.B., Bender, L.W., Pierce, T.E., and Petersen, W.B., (1989):
Air Quality Simulation Models from EPA. Environmental Software, 4(2):52-61.
U.S. Congress, (1963): Clean Air Act as Amended by Air Quality Act of
1967 (Public Law 90-148); The Clean Air Act Amendments of 1970 (Public Law
91-604); The Technical Amendments of 1973 (Public Law 92-157, Public Law 93-15,
and Public Law 93-319); and The Clean Air Act Amendments of 1977 (Public Law
95-95), United States Code, Title 42, '1857 et. seq.
Venkatram, A., (1988): Topics in Applied Modeling. In Lectures on Air
Pollution Modeling, A. Venkatram and J.C. Wyngaard (Editors). American
Meteorological Society. Boston, MA. pp. 267-324.
Weil, J.C., Sykes, R.I., and Venkatram, A., "Evaluating Air-Quality
Models: Review and Outlook", Journal of Applied Meteorology, Vol. 31, 1992, pp.
1121-1145.
APPENDIX - TERMINOLOGY
Atmospheric dispersion model:
Deterministic model:
Evaluation (or Validation):
Evaluation (or Validation) Objective:
Evaluation (or Validation) Procedure:
Fate:
Process Model (of a stochastic process):
Statistical Model (of a stochastic process):
Stochastic Process:
Uncertainty:
Variability:
Verification:
1 On assignment to the Office of Air Quality
Planning and Standards, U.S. Environmental Protection Agency

Scientists' Contributions